


Social scientists conducting field-based research often design and conduct their studies in isolation, making their findings difficult to replicate in other contexts. To address this challenge, a team of social scientists at UC Berkeley and other institutions launched an initiative called “Metaketa,” which aims to provide a structure and process for designing and coordinating studies in multiple field sites at once, leading to a more robust body of data and improved standards for transparency and verification.
Metaketa is a Basque word meaning “accumulation.” Funded via Evidence in Governance and Politics (EGAP), a research, evaluation, and learning network, the Metaketa Initiative represents a model for collaboration that “seeks to improve the accumulation of knowledge from field experiments on topics where academic researchers and policy practitioners share substantive interests,” according to the EGAP website. “The key idea of this initiative is to take a major question of policy importance for governance outcomes, identify an intervention that is tried, but not tested, and implement a cluster of coordinated research studies that can provide a reliable answer to the question.”
The model is grounded in eight principles: coordination across research teams; predefined themes and comparable interventions; comparable measures; integrated case selection; preregistration; third-party analysis; formal synthesis; and integrated publication.
Thad Dunning, Robson Professor of Political Science at UC Berkeley, helped launch the Metaketa Initiative, and he participated in the first “cluster” of studies, which focused on understanding how the dissemination of information about candidates influences voter behavior. In 2019, Dunning co-authored a research paper in Science Advances, “Voter information campaigns and political accountability: Cumulative findings from a preregistered meta-analysis of coordinated trials,” that summarizes the importance of the Metaketa model: “Limited replication, measurement heterogeneity, and publication biases may undermine the reliability of published research,” Dunning and his co-authors wrote. “We implemented a new approach to cumulative learning, coordinating the design of seven randomized controlled trials to be fielded in six countries by independent research teams. Uncommon for multisite trials in the social sciences, we jointly preregistered a meta-analysis of results in advance of seeing the data.”
 Dunning and the co-authors — including UC Berkeley political scientist Susan Hyde — also published a book, Information, Accountability, and Cumulative Learning: Lessons from Metaketa I, that shares lessons learned from the project. This collaborative Metaketa model has since been used for studies on taxation, natural resource governance, community policing, and women’s action committees and local services.
Dunning and the co-authors — including UC Berkeley political scientist Susan Hyde — also published a book, Information, Accountability, and Cumulative Learning: Lessons from Metaketa I, that shares lessons learned from the project. This collaborative Metaketa model has since been used for studies on taxation, natural resource governance, community policing, and women’s action committees and local services.
We interviewed Dunning about how the Metaketa Initiative evolved, as well as what his own study suggested about how information influences voters’ choices. (Note that questions and responses have been edited for clarity and content.)
What was the focus of the study that you undertook through the Metaketa Initiative?
The initial thrust of the study was focused on the connection between information provision and political accountability. It almost seems like a truism that information has to matter for politics, and yet we don’t actually know that much about how providing voters with certain kinds of information actually affects political behavior. We haven’t built a coherent body of evidence around that.
The second part was methodological, and had to do with how we build cumulative knowledge. There’s been a big movement in the social sciences toward experimentation as a way of building causal knowledge. That has some advantages, but it’s also really limited. Our project stepped away from a single study and said, here are some aggregate conclusions that might hold across settings. It was really trying to tackle the problem of external validity in experiments: if I find something in a particular study, does it generalize to other contexts?
How did the Metaketa model evolve into a formal initiative?
The methodological goal of the Metaketa was to try to design a study through collaboration across teams that would build in meta-analysis-ready data. That was a major objective. There were also objectives around the reporting of results, including more pre-specification and transparency in the analysis, and working toward this larger model of open science. All of those aspects were important in the project.
There’s a lot of value in academia in planting the flag and being the first one to do something, but maybe we’re a little bit too willing to move on. The idea is not to prioritize new models or innovation, but to prioritize replication, and that was a big part of the model. There have traditionally been a lot of problems in trying to generalize across studies. Often the studies themselves are not comparable. They have different kinds of interventions and outcome measures.
In many ways, we were crossing the river by feeling for stones. We’d been having discussions around this kind of model for quite some time. Part of the project was getting some initial grant funding to support the concept, and then to launch this first substantive part of it, focused on political accountability and information provision. It has been an interesting initiative to be involved in. There have now been four or five Metaketas on different substantive topics. It’s a model that’s been funded by different sources, but we had an anonymous donor who provided the funding for our startup, and more recently, the British government and USAID and others have been involved in funding these larger Metaketas.
How did you ensure that data from one study will align with that of the others?
A big part of this is just trying to harmonize the interventions: what kind of information is going to be provided? How do we conceptualize information in relation to information and political performance? What do voters think before information is provided? How does the information differ from what they already believed? We wanted to try to standardize this across projects, and measure in a symmetric way what outcomes we care about: first, whether voters vote and how they vote, but then also secondary outcomes. And we want to be able to do that consistently across studies. That way we can assess the average effect across the seven study sites, as well as variation across the sites. And we can look at that in a way that makes sense. A lot of that was harmonized at the design stage ex ante through a series of workshops across project teams. Then, sharing public data ex post allowed us to do a meta-analysis of data from the seven studies.
What did your study suggest about the role of information on voter behavior?
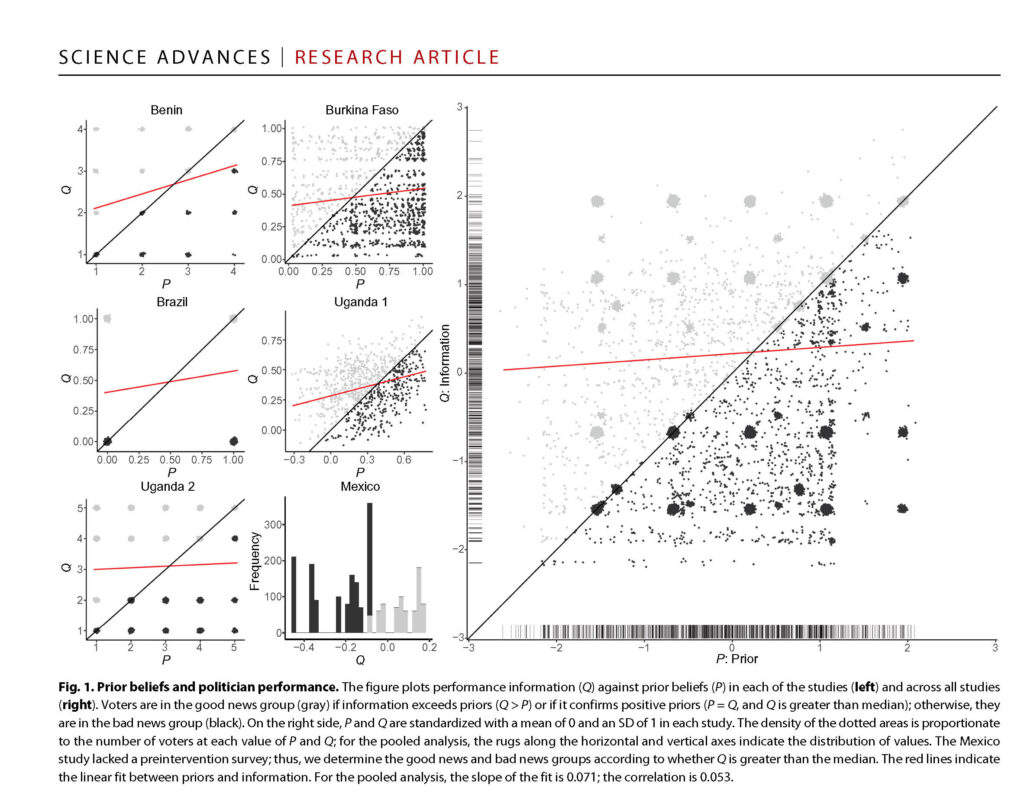 It seems self-evident that the information people receive would make a difference in how they vote, but our finding was a big no. Almost everywhere we looked, the provision of information made no difference in how people voted. We had taken a lot of care to try to develop designs that were well-powered enough, particularly once we aggregated the data across seven studies. We could make the claim with a fair degree of precision and certainty, in a statistical sense. That may make the answer itself more compelling and more credible, that the information provision didn’t have any effect.
It seems self-evident that the information people receive would make a difference in how they vote, but our finding was a big no. Almost everywhere we looked, the provision of information made no difference in how people voted. We had taken a lot of care to try to develop designs that were well-powered enough, particularly once we aggregated the data across seven studies. We could make the claim with a fair degree of precision and certainty, in a statistical sense. That may make the answer itself more compelling and more credible, that the information provision didn’t have any effect.
On the other hand, it may seem mystifying, given the important role we think information is playing in politics. What we can say is that providing this kind of information from neutral third parties about what politicians are doing in office, including about political malfeasance or misspending of funds, didn’t shape voters’ behavior. That’s depressing, but also may be informative. If we want to transform political accountability, maybe we should be looking at other kinds of interventions.
Politicians may think voters are more responsive than they seem to be in some of these instances. But voters can be hard to move, and that might be consistent with some of what we know about partisanship broadly. The idea that information doesn’t move people away from their pre-existing beliefs is a depressing finding from a number of perspectives, although you can’t test everything, and there’s a role for more sustained, cumulative evidence-gathering in some of these areas. I would have said ex ante that this kind of information provision would have mattered much more than it did.
Our methodological message is that we need to be careful and build up piece by piece, and then after having built up carefully, try to put a body of evidence together in an area. We don’t want to overclaim and then say, well, information doesn’t matter. But we do have robust evidence from these studies that this type of information provision doesn’t shape what voters do very much on average, across a wide set of contexts. We think that’s useful, even if not the final word. But we should evaluate other kinds of claims about other sorts of information, hopefully using similarly robust kinds of evidence. That’s the methodological point we want to drive home.
Do you think the Metaketa model could be used in other contexts, for instance among researchers on a single campus like UC Berkeley?
There’s a lot of ground for more collaboration, and this is consistent with an open science model. Often we have incentives to work in small teams, to claim priority to embark in new directions. Trying to work collaboratively to further knowledge is also really important, and there’s a big role for it. And it doesn’t all have to entail gathering seven teams in a room and planning a study in advance.
We’ve explored ideas like having a registry of study topics, where three studies would be conducted, and then a researcher would come along and replicate that set of studies, and also tweak them, building in innovation and replication at the same time. All of these things are potentially interesting. Many of them could also be interdisciplinary in character, speaking to the Matrix mission, and could be a way to bring people together from across disciplines. These approaches can have a big upside in terms of knowledge generation.


